What is K-means clustering?
The K-means clustering algorithm was developed by MacQueen. This algorithm is aimed to partition a set of objects based on their characteristics. After that the object can be partitioned into k clusters, where k is a predefined constant. We need a reference point to identify a clusters and this reference point is our k centroid. The centroid of a cluster is formed by the relative distance of all the object in that cluster.Simple implementation of Lloyd’s algorithm for performing k-means clustering in python:
import numpy as np
def cluster_points(X, mu):
clusters = {}
for x in X:
bestmukey = min([(i[0], np.linalg.norm(x-mu[i[0]])) \
for i in enumerate(mu)], key=lambda t:t[1])[0]
try:
clusters[bestmukey].append(x)
except KeyError:
clusters[bestmukey] = [x]
return clusters
def reevaluate_centers(mu, clusters):
newmu = []
keys = sorted(clusters.keys())
for k in keys:
newmu.append(np.mean(clusters[k], axis = 0))
return newmu
def has_converged(mu, oldmu):
return (set([tuple(a) for a in mu]) == set([tuple(a) for a in oldmu])
def find_centers(X, K):
# Initialize to K random centers
oldmu = random.sample(X, K)
mu = random.sample(X, K)
while not has_converged(mu, oldmu):
oldmu = mu
# Assign all points in X to clusters
clusters = cluster_points(X, mu)
# Reevaluate centers
mu = reevaluate_centers(oldmu, clusters)
return(mu, clusters)
def init_board_gauss(N, k):
n = float(N)/k
X = []
for i in range(k):
c = (random.uniform(-1, 1), random.uniform(-1, 1))
s = random.uniform(0.05,0.5)
x = []
while len(x) < n:
a, b = np.array([np.random.normal(c[0], s), np.random.normal(c[1], s)])
# Continue drawing points from the distribution in the range [-1,1]
if abs(a) < 1 and abs(b) < 1:
x.append([a,b])
X.extend(x)
X = np.array(X)[:N]
return X
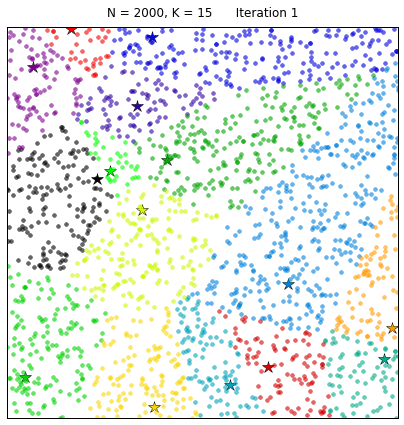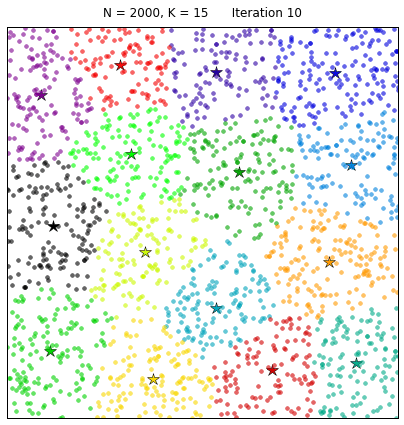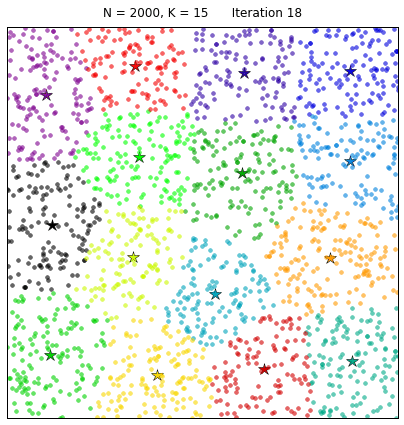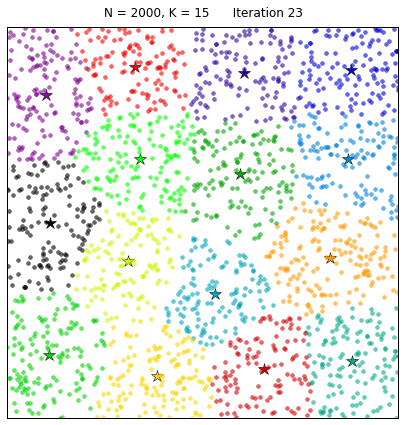
Application of Clustering using K-Means
There are many clustering approaches can be used to analyses web contents such as text-based clustering, link-based clustering and graph based clustering.Text-based clustering is based on the content of web document. The basis idea is that if two document contain many common words then it can be defined that two document are very similar. The text-based approaches can be further classified according to different clustering method such as partitional, hierarchal or graphical based.
Partitional clustering
The partitional document clustering approach attempt a flat partitioning of a set of documents into a predefined number of disjoint cluster. The most common partitional clustering algorithm is k-means, which relies on the idea of centroid can be a good representation of the cluster.
Graph based clustering
This clustering is relied on the edge detection. Each node represents a document and there exists an edge between two nodes if the document similarity between documents in different clusters. The basic idea is that the weights of the edges in the same cluster will be greater than the weights of the edges across clusters.The advantages of these approaches are that can capture the structure of the data and that they work effectively in high dimensional spaces. The disadvantage is that the graph must fit the memory.
Hi, Kevin, that's really a great piece of work which you have done. Just that I think it would be better if you could add more comments on the codes your wrote, that would be more easier for the people like me which are not familiar with programming to follow your idea.
回覆刪除HI, He Huang, I glad you like my work. The main ideal for the python code is using NumPy to do the N-dimensional array calculation and do the graphical presentation for the K-Means.
回覆刪除NumPy's main object is the homogeneous multidimensional array. It is a table of elements (usually numbers), all of the same type, indexed by a tuple of positive integers. In Numpy dimensions are called axes. The number of axes is rank.
For example, the coordinates of a point in 3D space [1, 2, 1] is an array of rank 1, because it has one axis. That axis has a length of 3. In example pictured below, the array has rank 2 (it is 2-dimensional). The first dimension (axis) has a length of 2, the second dimension has a length of 3.
K-means is classic algorithm for clustering. Your blog includes implementation details about the algorithm. It's really worth reading.
回覆刪除This blog really helps me. Now I am also doing some thing with Numpy. Thank for your sharing.
回覆刪除