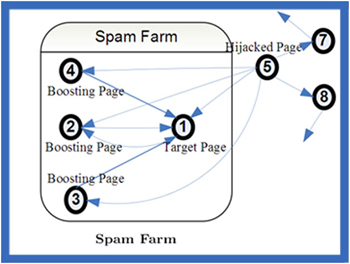
After the lecture I did some research on the underlying principles, data science, history, and design pattern.
Here are a on line article which is talking about the design pattern for the recommendation systems.
Firstly, recommender systems are essentially predictive analytics engines. It is starting with some training data which is collected from end customer or users. There are an important assumption - the web usage and purchase patterns of a particular customer relative to previous customers and a variety of similarity calculations, the engine can predict what each particular customer is most likely to do next, such as what is their next page or what items will be purchased next.
The analytics engines basically is constructed by historical logs and a supervised machine learning algorithm.
Design Patterns for Recommendation Systems
The definition of Design Patterns is "a general repeatable solution to a commonly occurring problem; a description or template for how to solve a problem that can be used in many different situations." So for our recommendation system is how to design a recommendation engine.
There are 4 different design patterns for the recommendation engine design:
co-occurrence matrices, vector space models, Markov models, and "everyone gets a pony (the most popular item)".

1. The co-occurrence matrix is the cross-matrix of all possible product pairs product A and product B that were co-purchased by prior customers. Analysis of non-zero elements in this matrix identifies which co-occurrences are anomalous, that is, are more frequent than you would expect by independent occurrence of items. These anomalous co-occurrences become indicators for potential offers of product B for customers who buy product A. This approach is based upon the association rule mining algorithm.

2. Vector space models are used to describe customer modeling and product modeling. This begins with building a feature vector, consisting of either a set of features that describe a customer such as products of interest, features of interest, manufacturers of interest, purchase frequency, price range, etc. or a set of features that describe a product . Cosine similarity calculations are then made against these feature vectors to identify similar customers (X,Y) and similar products (A,B). In the first case, products are offered to customer X based upon the purchase history of similar customer Y. In the second case, the customer is offered product A based upon its similarity to product B that the customer has previously purchased or has recently looked at (but not purchased).

3. Markov models are a form of probabilistic model that can be used to predict elements of a sequence, usually a temporal sequence (e.g., the weather, the stock market, network traffic, web clicks within a site, or purchase patterns). Markov models have a restricted form, mathematically speaking, and this restriction can sometimes make it possible to learn a Markov model from past data (training data). This model can be used to predict probabilities of future events, such as the next most likely thing that the customer will do or buy.

4. "Everyone Gets a Pony?" this model is the world?s simplest. After you find the items that everyone likes and nearly everyone else has purchased, then you offer those items to every new customer, since they too may buy them. This "Top 40" model is not very interesting and does not require a complex learning model, but the product may be a guaranteed seller. Such a simplistic model may be most useful in on line stores that have a specific branding and that also have other popular items that customers may not be aware of. Consequently, you want to make customers aware of those popular off-brand items while they are still shopping in your store.